

RAG Does Not Fix Hallucinations. It Just Makes Them Quieter.
11.03.2026
A confusion matrix, or an error matrix, is a table describing the performance of the classification (classification can be performed via expert rule - single or multiple or a predictive model). For our fraud-related use case, it will be sufficient to work with a binary classifier – fraud / non-fraud.
Each row of the table represents an instance in the actual class
Each column of the table represents an instance in the predicted class
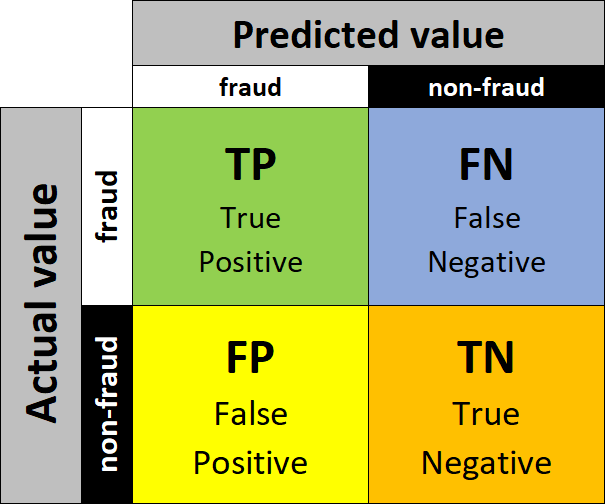
(*sometimes the rows and columns are reversed and rows represent predicted values and columns represent actual values)
From the above description and the diagram, we see that four outcomes can be reached:

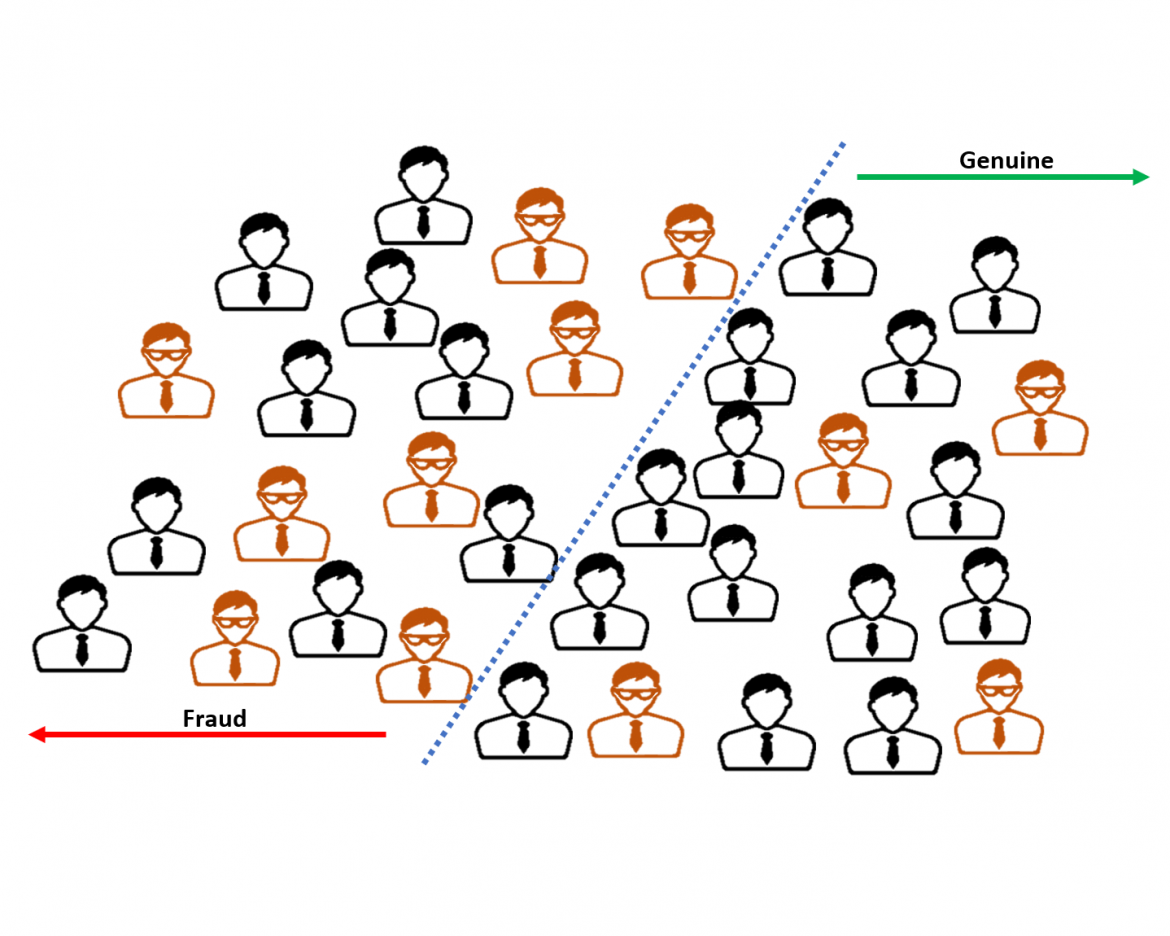
Imagine we have a dataset of 100 customers with fraudsters among genuine customers. By using our preferred detection technique, we classify all of the customers as fraudsters (all pink highlighted) or genuine customers (all blue highlighted are considered genuine).

From the picture, it is clear that our technique is not 100% accurate, as we can see genuine customers among the assumed fraudsters and fraudsters among the classified genuine customers. It's easy to see from the picture below that actual fraudsters are classified as True-Positive (green-colored) when we correctly identify them as fraudsters. Those fraudsters we missed we call as False-Negatives (blue-colored), and we further try to improve our detection technique to identify them as fraudsters next time.

Now we are left with genuine customers; if we correctly classify them as genuine, those are True-Negatives (orange-colored). On the other hand, those genuine customers we classified as fraudsters - those are (famously known) as False-Positives (yellow-colored), and because of our incorrect classification, we might have annoyed them despite them being good customers - so this is the extremely important group/figure many fraud experts are trying to minimize.
The confusion matrix will allow us to review the most important KPIs - measuring the efficacy of a rule, analytical model, or even overall fraud detection system. Let's use the above sample of 100 customers, of which 15 are fraudsters and 85 are genuine = non-fraudulent. Now our confusion matrix would look like this:
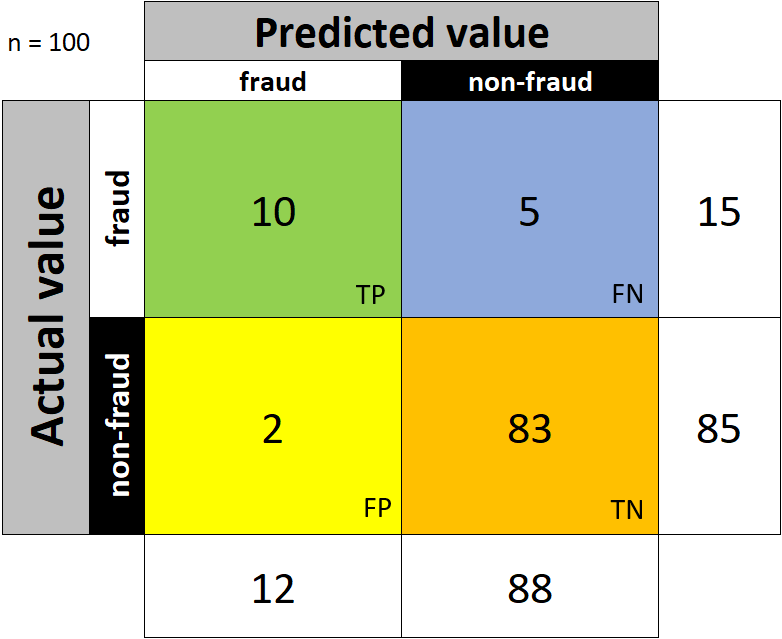
Now we will go through the most common metrics that are used to describe the efficiency of fraud detection:
True Positive Rate (TPR, also known as Sensitivity, Recall or Hit rate, higher is better) - measures how often the system flags actual fraudulent occurrences as fraud
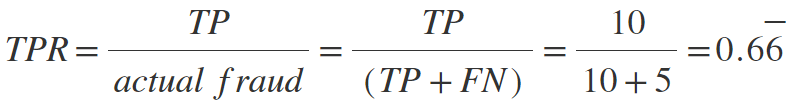
False Negative Rate (FNR also known as miss rate, lower is better) measures how often the system misses fraud among fraudulent occurences
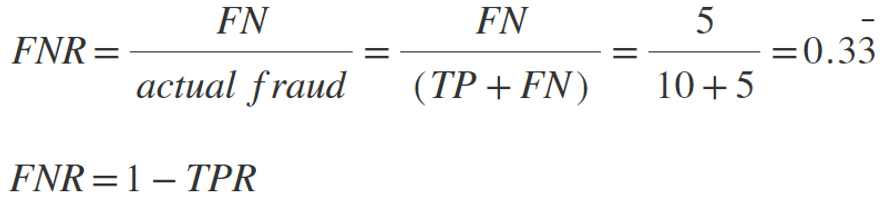
False Positive Rate (FPR also known as fall-out, lower is better) - measures how often the system flags an occurrence as fraudulent though it is not
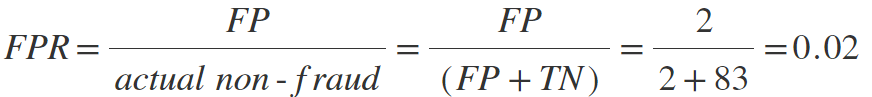
True Negative Rate (TNR also known as Specificity, Selectivity, higher is better) measures how often the system classifies non-fraud among non-frauds
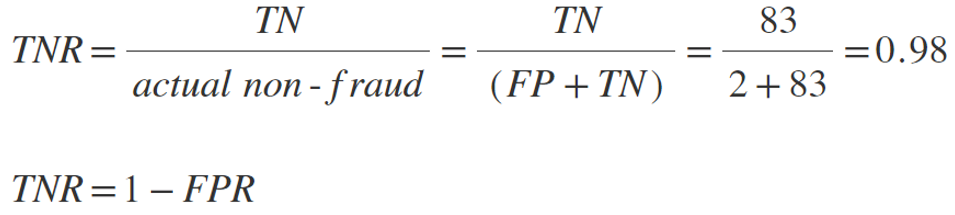
Accuracy (ACC, higher is better) describes how often the system flags a fraudulent occurrence as fraud and as non-fraud when it is not a fraudulent event
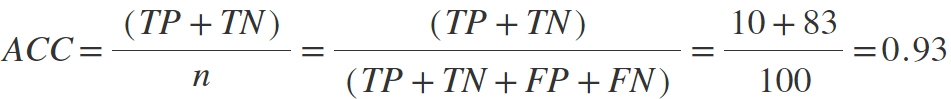

For our adjusted example from above (only 1 TP instead of 10), we would be able to calculate the Balanced Accuracy and see that lower TPR significantly pulls down the overall score:
Positive Predictive Value (PPV, also known as Precision, higher is better) describes the measure of when the system flags an occurrence as fraudulent and how often it is correct.
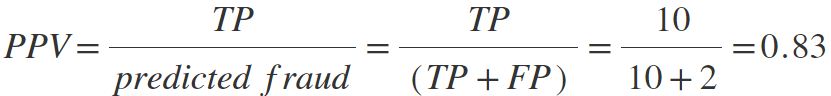
Misclassification rate (lower is better) shows how often is the fraud detection system wrong (considers only wrongly classified frauds and wrongly classified non-frauds).
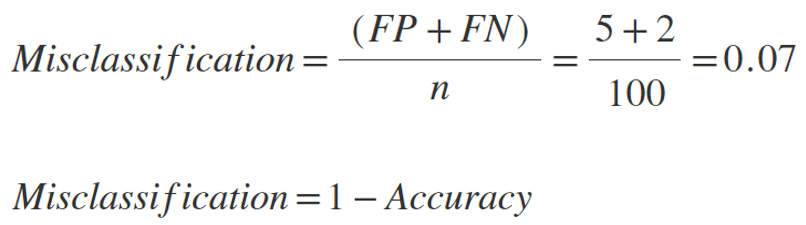
F1-Score (higher is better) is a measure combining precision (PPV) along with True-Positive rate (TPR) and is commonly described as a harmonic(harmonic because the ratio between the weight of PPV and TPR is equal 1:1) mean between these two measures. This is also an extremely valuable metric as it is very sensitive when precision or recall is very low and similar to balanced accuracy considering multiple characteristics simultaneously.
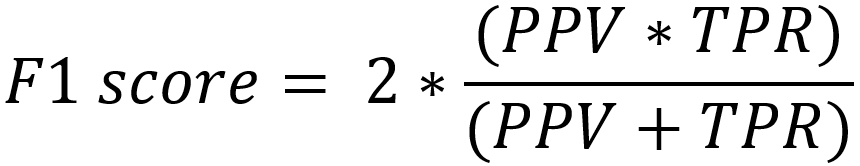
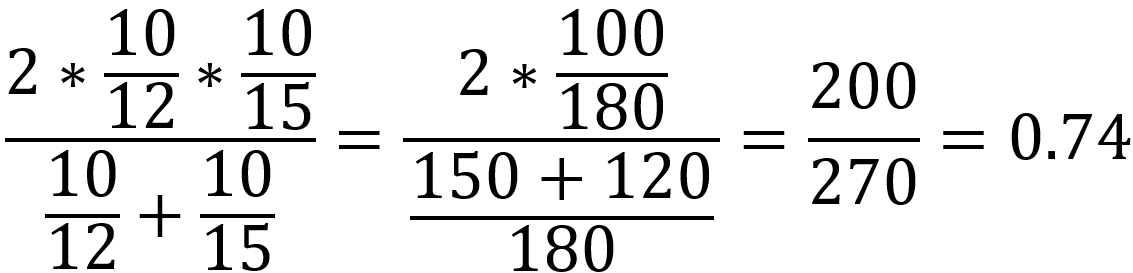
Sometimes this extreme focus on the False-Positive Ratio comes from the above-mentioned impact - genuine customers misclassified as fraudsters and the practical operational impact on the staff performing alerts review and resolution within the organization. Observed false positives are very tangible for the staff interacting with genuine customers. A repetitive negative experience can quickly decrease trust in the fraud system. This also becomes a severe internal inconvenience for the staff esp. when they need to contact alerted customers, and a significant number of their calls will result in a false positive/false alert.
This can become even more tangible when investigation resources or call center agents are not directly reporting to the fraud business unit. Depending on the organization's size and practices, such resources might fill in more than one role, and on top of their responsibilities as fraud alert resolution agents, they could also fill in as customer service center agents.
Nevertheless, the danger here is that for the fraud business unit, the FPR becomes the single metric by which the efficacy is measured and as an attempt to mitigate the risk of issues being raised by the call center manager or other business unit owning this part of the process.
As seen in the above paragraphs, FPR is important, although just one metric describing specific characteristics of the system. If we start to focus solely on FPR, we can easily reach whatever threshold we feel is satisfactory just by making the rule/s more strict or more focused.
For example, let's have a rule which alerts the first transactions of the cards issued within the last seven days, initiated from high-risk countries. FPR is, for example, 30% (30 out of 100 non-frauds are flagged as fraud). We analyzed recent past frauds, and we observed that 70% of the fraudulent transactions are above 100EUR, and around 50% of the fraudulent transactions are above 250EUR. To reduce FPR, we decided to adjust the rule to be more focused, and we can add another condition when only transactions greater than 100 EUR are alerted. Such adjustment might lower the FPR to, let's say, 20%. To further reduce FPR, we can increase the threshold amount to 250EUR and get a further reduction of FPR = 9%, which might be below our acceptable threshold of 10%.
From the above example, it should be evident that such an approach will reduce FPR but might impact other important metrics, like True Positive Rate. So though we get very few false positives from the given rule, we might also miss more actual frauds than before with more relaxed conditions.
Now we come to the point where we see that focusing on one of the above metrics only is not the best approach. We should look at multiple metrics when attempting to reduce FPR or choose a metric that incorporates multiple above-mentioned rates together (e.g, Balanced Accuracy or F1-score).
Any fine-tuning effort that is trying to address the high FPR of a particular rule needs to remember that other measures might be equally if not more important, to keep the system's fraud detection capability balanced and on the highest possible levels. Also, it is extremely important to use meaningful-sized datasets when validating the efficacy and remember the nature of the fraud, where the ratio of frauds vs. no-frauds is heavily imbalanced in favor of genuine transactions, which will impact certain metrics.














{kind=link}