


RAG Does Not Fix Hallucinations. It Just Makes Them Quieter.
11.03.2026
A bank runs a polished AI proof-of-concept. The demo is impressive. The chatbot answers perfectly. The slide deck promises 40% cost reduction, 60% faster investigations, and "near-human reasoning."
Then the room goes quiet.
Someone asks: "What happens when this model changes next quarter?"
That silence is not fear of AI. It is fatigue from AI hype.
To be clear: the capabilities are real. LLMs have unlocked genuine breakthroughs - summarizing complex cases in seconds, extracting patterns from unstructured data, and augmenting analysts in ways that were impossible two years ago. The opportunity is substantial.
But ironically, the explosive success of large language models may now be one of the biggest blockers to serious AI adoption in regulated, operationally complex environments.
The technology is moving faster than organizations can responsibly absorb it. This is not resistance to automation, analytics, or even AI. Banks, insurers, telcos, and regulators already use models everywhere.
The hesitation is far more specific and far more rational. It stems from LLMs being positioned as near-universal solutions while
I'd like to dig deeper into these four distinct distortions we've observed repeatedly with our customers.
The LLM boom created a new startup archetype: thin application layers, prompt-engineered workflows, heavy reliance on third-party foundation models, and aggressive claims of "AI-native disruption."
Many of these companies do not sell products. They sell narratives - amplified relentlessly on social media, creating noise that distorts buyer perception and makes it increasingly difficult to distinguish genuine capability from marketing theater.
The assumption that LLM wrappers can generate billion-dollar valuations within months has flooded the market with solutions that look brilliant in demos but collapse under operational pressure - breaking on noisy data or failing silently in edge cases.
For customers: if the intelligence sits outside your control, can you really own the risk?
A frequent illustration appears in RAG-based internal research assistants deployed to support fraud analysts and investigators. These tools are positioned as low-risk - read-only access to fraud typologies, escalation policies, regulatory guidance, and precedent cases. In practice, relevance tuning, chunking strategies, and retrieval logic evolve continuously as teams chase better answers. Seemingly harmless adjustments change which documents surface, which passages are emphasized, and which sources are omitted. Analysts begin to receive different “authoritative” answers to the same question over time. When asked to justify a decision or explain why guidance differed between two similar cases months apart, teams struggle to reproduce prior outputs or demonstrate what information the system relied on at the time.
What begins as a productivity aid quietly becomes an interpretive layer between policy and practice - without the governance normally applied to either.
The problem is compounded by a “ship now, fix later” mentality. Wrapper companies and internal teams alike push early versions into production. Then make non-transparent changes over time.
Prompts are adjusted, retrieval logic modified, guardrails refined, response formats altered - often without formal change management or communication. Users discover these shifts only when workflows break or outputs behave differently. The result is a system that evolves non-deterministically, making it nearly impossible to audit historical decisions or explain to a regulator why AI-assisted outcomes were consistent last quarter but inconsistent today.
Beyond wrapper companies emerges a deeper structural risk: dependency on foundation models that evolve outside your control.
For decisioning platforms, even small upstream changes trigger significant consequences: drift in explanations, inconsistent decisions, broken integrations, re-validation cycles with compliance - requiring weeks of documentation and approval before returning to production. Organizations that fine-tuned models or built workflows around specific behaviors find their investments invalidated by changes they cannot control.
The irony: the more powerful models become, the harder they are to operationalize safely. Teams must choose between staying current - with all the validation overhead - or freezing on older versions that may lose support. Neither option is comfortable.
A few years ago, technology roadmaps were more predictable. Today, decision-makers face questions with no stable answers. Should we build now or wait six months? Should we invest in fine-tuning or RAG? What if a dramatically cheaper model outperforms our current stack tomorrow?

The DeepSeek moment crystallized this anxiety. When a model with a fraction of the training cost achieves comparable results to industry leaders, every assumption about AI economics comes into question.
Simultaneous improvements are appearing across multiple steps in the LLM training and inference workflow, and new tools addressing these upgrades emerge weekly. This creates a freeze effect. Not because leaders don't believe in AI, but because they don't trust the stability of today's choices. The rational response to radical uncertainty is often to wait and in fraud prevention, hesitation frequently feels safer than commitment.
The tragedy is that this waiting is not free. Organizations that delay adoption entirely fall behind not just technically, but in institutional learning - the hands-on experience needed to deploy these technologies effectively. Meanwhile, talent capable of navigating this landscape grows restless and leaves for organizations willing to experiment.
There is a paradox that fraud professionals should appreciate: the very technology deployed to fight fraud introduces new vulnerabilities that adversaries are already learning to exploit.
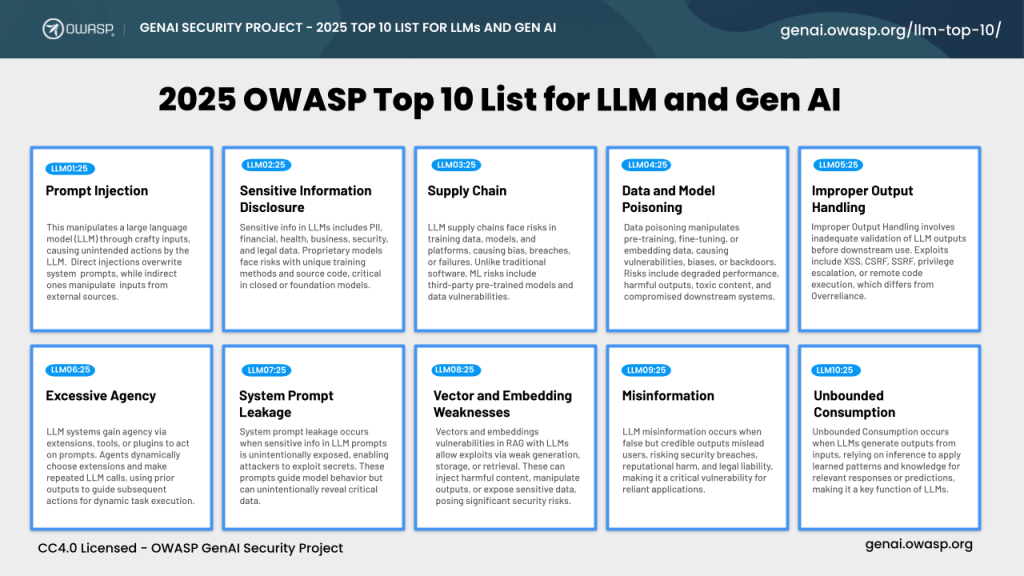
Integrating LLMs into enterprise stacks opens attack surfaces most organizations are not equipped to monitor, let alone defend:
The paradox for fraud prevention: the same capabilities that make LLMs useful - contextual reasoning, pattern recognition, natural language understanding - also make them difficult to secure and monitor. Traditional access controls do not map to systems whose behavior emerges from probabilistic inference.
This does not mean LLMs should be avoided. It means security and data governance must be integral from the beginning, not bolted on afterward. Frameworks like ISO 42001 can help surface these risks systematically. And fraud teams, who understand adversarial thinking better than most, should lead these conversations rather than defer to IT or vendor assurances.
Fraud systems are not playgrounds. They require explainability for regulators and customers. They demand repeatability for consistent treatment. They need auditability for compliance. They depend on controlled change management. They operate over long lifecycles where decisions made years ago still affect current operations.
LLMs are probabilistic, fast-evolving, and often opaque. This mismatch creates friction when LLMs are positioned as replacements for existing controls rather than components within a broader architecture.
The real danger is not overusing AI. It is misplacing it - deploying LLMs in roles that require the determinism and stability they cannot provide, while underutilizing them in roles where their flexibility and reasoning capabilities would genuinely add value.
The path forward is not rejection. It is architectural humility. LLMs work best when embedded as augmentation rather than authority, constrained by rules, scores, and context, used for summarization, enrichment, and assistance, and separated from final decision logic.
In fraud terms: let models assist analysts, not replace controls. Let LLMs explain, not decide. Let deterministic systems remain the backbone while probabilistic systems enhance the edges.
This is Composite AI in practice - combining the strengths of different AI approaches while mitigating their individual weaknesses. Rules handle what rules handle well. Machine learning handles pattern recognition. LLMs handle natural language understanding and generation. Each technology operates in its zone of competence.

Before adopting an LLM-driven capability, ask these questions:
If the answer to these questions is "we don't know yet," that is not failure. It is a signal to slow down, design more carefully, and build in appropriate safeguards before scaling.
The biggest blocker to AI adoption in fraud prevention is not the technology itself. It is confusion between research velocity and production readiness, demos and operations, cleverness and consistency, expectations and organizational maturity.
LLMs did not create this problem. They exposed it.
What has changed is the speed at which the gap now matters. LLMs compress innovation cycles so aggressively that decisions made without governance, validation, and operational discipline unravel faster than organizations can respond. Adoption fails not because technology moves too slowly, but because it moves faster than trust and control mechanisms can keep up.
In fraud prevention, boring reliability consistently beats spectacular demos. Systems that behave predictably, can be explained under scrutiny, and survive personnel turnover, model updates, and regulatory review are the systems that actually protect customers and institutions.
This is not conservatism. It is professionalism.
The question is not whether LLMs will influence fraud operations - they already do. The question is whether their influence is deliberate, governed, and understood, or accidental and unmanaged.
References:
[4] https://afedercooper.info/paper/cooper2025books.pdf
[5] https://letstalkfraud.com/from-hype-to-reality-fighting-fraud-with-composite-ai













