


Mastering Fraud Solution Implementation - Success? Depends Who You Ask.
23.07.2026
Picture this. You are a fraud analyst at a mid-sized bank. Your team just deployed a shiny new AI assistant that actually reads your internal documents - your AML policy, typology library, and five years of case notes - before answering questions. The vendor promised it would "eliminate hallucinations."
So you ask: "Does this transaction pattern match any known trade-based money laundering typology in our internal guidance?"
The AI confidently cites a specific internal document, references a 2022 case, and maps the pattern to a known typology. Thorough. Convincing. Footnoted.
The only problem? That case from 2022 never existed. The AI read your documents, found something vaguely related, and filled in the gaps with plausible fiction.
Welcome to Retrieval-Augmented Generation (RAG) - where the hallucination problem gets smaller, but does not disappear.
Retrieval-Augmented Generation (RAG) is an AI architecture that adds a retrieval step before generating a response. Think of the difference between asking a colleague something off the top of their head versus asking them to check the filing cabinet first. RAG is the filing cabinet version.
A standard LLM is trained once, then frozen. It knows nothing about your institution's policies, your internal case history, or last week's fraud alert. RAG fixes this by dynamically injecting relevant content from your own document library into the model's prompt at query time.
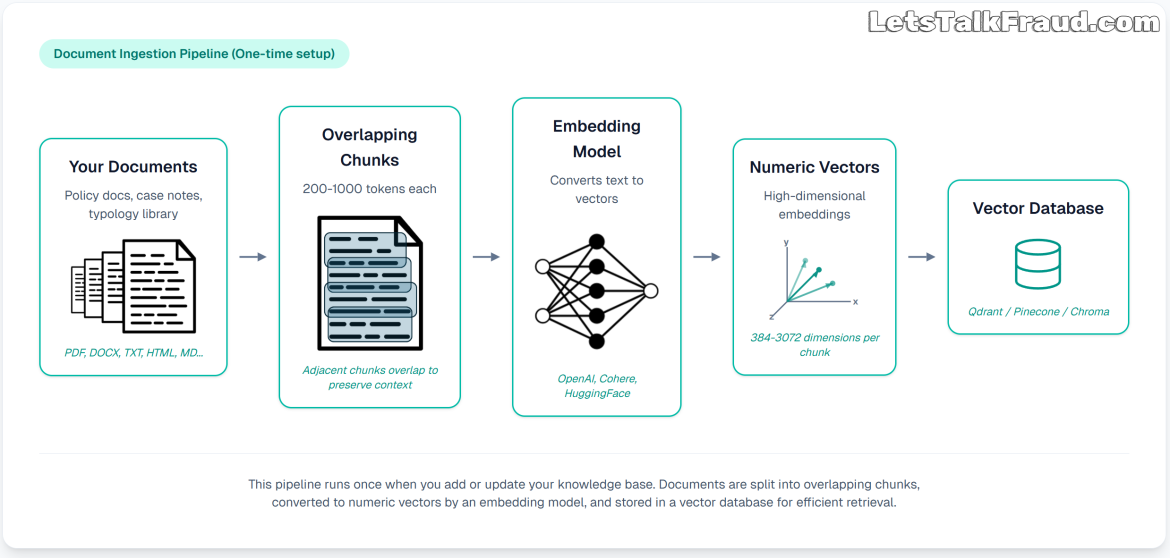
The mechanics work in the following steps:
If you like things a bit more technical: Modern embedding models are built on the transformer architecture (the same foundation as GPT and BERT) but trained with a specific objective: make semantically similar texts produce vectors that are close together in the output space, and semantically dissimilar texts produce vectors that are far apart. Models typically produce vectors of 384 to 3,072 dimensions, depending on the model. More dimensions generally mean greater expressive power but higher storage and compute costs.
In simple terms: your 500-token chunk of text becomes a list of, say, 768 floating-point numbers. Your query becomes another list of 768 numbers. The database finds which stored lists are most geometrically similar to your query list. Those chunks get pulled out as text and handed to the LLM. How many of them are pulled depends on the context window length within which they have to fit.
Modern models advertise context windows of 128,000 or even 200,000 tokens. On paper, this sounds like it solves the chunking problem entirely - just send all your documents and let the model find what it needs.
In practice, it does not work that way. Research has documented a "Lost in the Middle" effect where LLMs consistently struggle with information placed in the middle of long prompts - early and late content gets attention, middle content gets lost. More critically, the model's own parametric memory - everything it absorbed during training - increasingly competes with your retrieved documents as context grows. At some point, the model starts trusting its own knowledge more than the documents you handed it.
The context window on the spec sheet is not the same as the usable context window in your deployment. Testing at your actual production context length is not optional.

Three independent studies have now measured RAG hallucination rates directly. They all arrived at the same uncomfortable conclusion.
The largest, from Kamiwaza AI (March 2026), evaluated 35 language models across three context lengths, four temperature settings, and three hardware platforms, consuming 172 billion tokens of inference. That is not a typo - 172 billion. The author clearly had questionable weekend plans and a generous GPU budget.
The methodology was built around a simple, clever idea: generate synthetic documents from a known database of facts, then ask models questions about entities that do and do not exist in those documents. Any confident answer about a non-existent entity is definitely a fabrication. No ambiguity, no LLM judge.
The results: under the best possible conditions, with 32,000 tokens, the top model (GLM 4.5) fabricated 1.19 percent of the answers. Realistic top-tier deployments sit at 5 to 7 percent. The median model across all 35 tested invented approximately one in four answers about things not in the documents. At 200,000 token context, no model stayed below 10 percent fabrication - not one.
Two additional findings are directly relevant to fraud teams. First, the model family predicts fabrication resistance better than the model size. Llama 3.1, with 405 billion parameters, fabricated 26.5 percent of the answers. A much smaller GLM model fabricated under 2 percent. Bigger is not safer. Second, and more unsettling: grounding ability and fabrication resistance are distinct capabilities. Llama 3.1 70B correctly extracted facts from documents 90 percent of the time - excellent retrieval - yet fabricated answers to nearly 50 percent of questions about entities that did not appear anywhere in those documents. A model can be simultaneously good at finding real facts and equally good at inventing missing ones.
RAGTruth (ACL 2024) assembled 18,000 annotated RAG responses and confirmed the same pattern. It also tested whether a second LLM could catch the hallucinations of the first - GPT-4 Turbo, as a hallucination detector achieved an F1 score of 63.4 percent. You cannot solve a hallucination problem by asking another LLM to proofread.
ReDeEP (ICLR 2025) explained the mechanism. Hallucinations in RAG occur when the model's internal knowledge overrides the retrieved context, while the attention mechanisms responsible for copying from retrieved documents fail to do their job. The model's own memory fights the documents you gave it, and sometimes wins. This explains why handing a model the correct answer does not guarantee it will use it.
RAG is genuinely valuable in fraud and financial crime work. Analyst assistance is the obvious application: retrieving actual internal typologies before answering pattern-matching questions, rather than relying on training data. Policy Q&A, where answers live in documents that change regularly, is a strong fit. So is surfacing similar historical cases when reviewing a new one - institutional memory made queryable. Regulatory change management is particularly compelling: updating the document library takes hours, retraining a model takes months.
The risk concentrates at the edges of your document coverage. When a user asks about something not in the library - a new typology, an emerging scheme, a regulation not yet ingested - the model will frequently generate a plausible-sounding answer anyway rather than admitting it does not know. In fraud prevention, that is exactly the scenario where a fabricated answer causes the most damage.
Test fabrication, not just grounding. Standard RAG evaluations test whether the model correctly answers answerable questions. You also need trap questions - queries about typologies or policies that do not exist in your library. If the model answers those confidently, you have a problem.
Test at production context length. A model that behaves at 8,000 tokens may degrade significantly at the 40,000 to 80,000 tokens your multi-document queries actually use.
Rethink temperature zero. The RIKER study found that T=0.0 increased fabrication rates for the majority of models and caused coherence failures at long contexts up to 48 times more often than T=1.0. A moderate temperature of 0.4 or 0.7 frequently performs better overall.
What do we mean by temperature:
Keep humans in the loop for high-stakes decisions. SAR filing, case escalation, customer blocking - RAG-assisted analysis should feed into a review step, not replace one.
RAG is one of the most practical AI architectures available to fraud teams today. It grounds responses in your own knowledge base and genuinely reduces hallucination compared to a standalone LLM. Use it.
But the research is unambiguous: RAG reduces hallucination; it does not eliminate it. The floor - even under ideal conditions with the best models - is 1 to 7 percent fabrication at short contexts, rising steeply from there. For median models at longer contexts, you are looking at one in four invented answers.
The vendors who told you RAG eliminates hallucination were selling. The researchers who consumed 172 billion tokens were measuring.
>> Use RAG. Build safeguards. Test at deployment conditions. And when the AI confidently cites a case from 2022 that you cannot find anywhere - trust your instincts.
Roig, J.V. (2026). How Much Do LLMs Hallucinate in Document Q&A Scenarios? A 172-Billion-Token Study Across Temperatures, Context Lengths, and Hardware Platforms. arXiv:2603.08274.
Niu, C., Wu, Y., Zhu, J., Xu, S., Shum, K., Zhong, R., Song, J., and Zhang, T. (2024). RAGTruth: A Hallucination Corpus for Developing Trustworthy Retrieval-Augmented Language Models. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL 2024), Bangkok, Thailand.
Sun, Z. et al. (2025). ReDeEP: Detecting Hallucination in Retrieval-Augmented Generation via Mechanistic Interpretability. International Conference on Learning Representations (ICLR 2025).
Liu, N.F., Lin, K., Hewitt, J., Paranjape, A., Bevilacqua, M., Petroni, F., and Liang, P. (2024). Lost in the Middle: How Language Models Use Long Contexts. Transactions of the Association for Computational Linguistics, 12:157-173.













